

زبان برنامه نویسی #پایتون ( #Python ) نیاز روز بوده و کارهایی از ساخت و مدیریت وب سایت ها گرفته تا تحلیل و اداره داده ها را انجام می دهد. وقتی تحلیلگران، مهندسان و #متخصصان_داده به پایتون اعتماد می کنند، کارکردهای واقعی آن نمایان می شود. نام پایتون مترادف با علم داده است، زیرا بصورت گسترده ای برای مدیریت و کسب بینش از داده ها استفاده می شود.
پایتون یک زبان برنامه نویسی همه منظوره و چند وجهی است که با استفاده از نگارش ساده، کتابخانه های خاص و کارکرد های تحلیلی، مورد رضایت افراد می باشد. اکثر کتابخانه های پایتون برای تحلیل دقیق، مصورسازی، محاسبات عددی و حتی یادگیری ماشین مفید هستند.
چند تا از بهترین کتابخانه های پایتون برای علم داده بشرح زیر هستند :
1. Pandas
2. NumPy
3. Scikit-Learn
4. Matplotlib
5. Seaborn
Pandas
Pandas یا کتابخانه تحلیل داده، یکی از رایج ترین کتابخانه های مورد استفاده در پایتون است. انعطاف پذیری، چابکی و مجموعه توابع، آنرا به یکی از محبوب ترین کتابخانه ها تبدیل کرده است. این کتابخانه هر آنچه برای خواندن، دستکاری، تجمیع و #مصورسازی_داده_ها و تبدیل به قالب های قابل درک لازم است را دارا می باشد. میتوان به پایگاههای داده از نوع CSV، TSV یا حتی SQL متصل شد و داده ها را به dataframe منتقل کرد که تقریباً معادل یک جدول آماری یا یک صفحه گسترده اکسل است. اینکار در مثال زیر نشان داده شده است:

برخی از ویژگی های این کتابخانه عبارتند از :
• ایندکس گذاری، دستکاری، تغییر نام، مرتبسازی و ادغام منابع داده
• اضافه، تغییر یا حذف ستون های داده
• مدیریت داده های تهی یا NAN
• ترسیم و چاپ اطلاعات
NumPy
همانطور که از نام این کتابخانه بر می آید، برای پردازش آرایه ها بکار رفته و بدلیل توانایی مدیریت آرایه های چند بعدی برای ارزیابی داده های چند بعدی استفاده می شود. نوع داده همه عناصر این کتابخانه یکسان است. ابعاد بعنوان محور و تعداد محورها بعنوان رتبه شناخته می شوند. یک آرایه در NumPy بصورت ndarray شناخته می شود. برای انجام محاسبات آماری یا عملیات ریاضی مختلف NumPy اولین انتخاب می باشد. مثال زیر تعریف آرایه های یک بعدی و چند بعدی را نشان می دهد:

کد زیر هم تغییر شکل آرایه را نشان می دهد :

برخی از ویژگی های NumPy عبارت است از:
• انجام عملیات پایه روی آرایه ها مانند جمع، تفریق، برش، مسطح کردن، ایندکس گذاری و تغییر شکل آرایه ها.
• انجام روال های پیشرفته پشته، تقسیم و پخش
• انجام عملیات جبر خطی و زمان (تاریخ و ساعت)
• انجام عملیات آماری
Scikit-Learn
#یادگیری_ماشین بخشی جدایی ناپذیر از زندگی متخصص داده است، بویژه اینکه مبنای هر نوع اتوماسیونی، یادگیری ماشین می باشد.
Scikit-Learn کتابخانه یادگیری ماشین پایتون است که انجام الگوریتم های زیر را برای متخصصان داده فراهم می کند:
• SVMs
• Random forests
• K-means clustering
• Spectral clustering
• Mean shift, and
• Cross-validation
از این کتابخانه برای اجرای الگوریتم های یادگیری با نظارت و بی نظارت در پایتون استفاده می شود.
برخی ویژگی های Scikit-Learn بصورت زیر می باشند :
• طبقه بندی
• خوشه بندی
• رگرسیون
• کاهش ابعاد
• انتخاب مدل
• پیش پردازش داده
Scikit-Learn داده ها را مدل می کند ولی آنها را به هیچ وجه دستکاری نمی کند. استنتاج های بدست آمده از این الگوریتم ها جنبه های مهمی از مدل های یادگیری ماشین ارائه می دهند.
Matplotlib
این کتابخانه برای مصورسازی داده ها شامل تشریح داده ها، تصویر دوبعدی و ترسیم اطلاعات استفاده می شود. مصور سازی داده ها به شکل های مختلفی انجام می شود، از قبیل نمودارهای histograms, scatter plots, bar plots, area plots, pie plots
علاوه بر این، می توان نمودارهای زیر را برای داده ها مورد استفاده قرار داد:
• Pie charts
• Stem plots
• Contour plots
• Quiver plots
• Spectrograms
برای مثال کد زیر نمودار یک آرایه را رسم می کند :

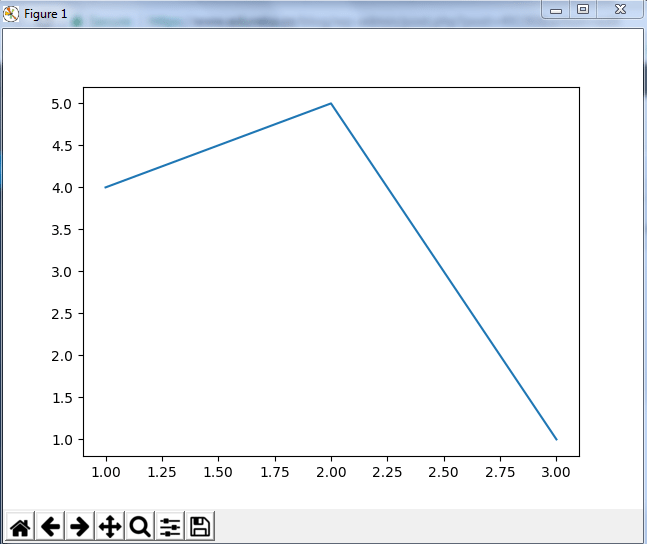
Seaborn
Seaborn یکی دیگر از کتابخانه های مصورسازی داده در پایتون است. ولی تفاوت Seaborn با Matplotlib در نوع مصورسازی است. با Matplotlib فقط می توان نمودارهای پایه از قبیل میله ای، خطی، منطقه ای، پراکندگی و غیره ایجاد کنید اما با Seaborn می توان انواع ترسیم های مختلف را با پیچیدگی در اجرای کمتری انجام داد. بعبارت دیگر، می توان با ارتقاء مهارت های مصور سازی بر اساس نیاز خود از Seaborn استفاده نمود.
در زیر نمونه هایی از گراف های تهیه شده با این کتابخانه نشان داده شده است:
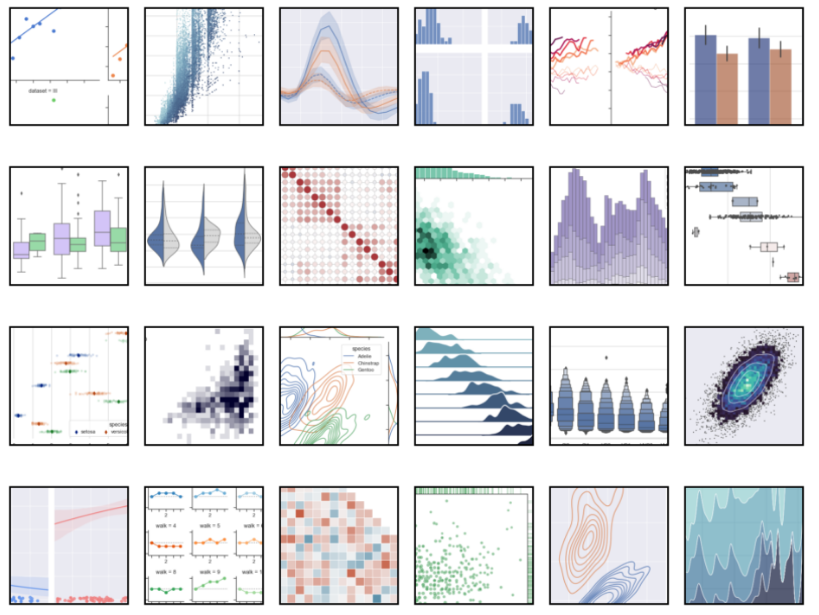
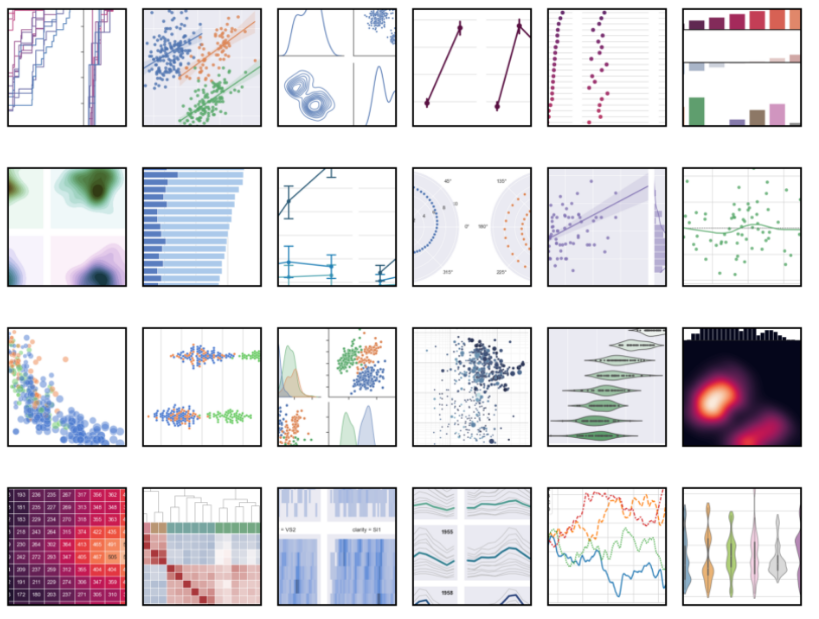
برخی از ویژگی های Seaborn بصورت زیر هستند :
• تعیین روابط مد نظر بین متغیرهای مختلف برای ایجاد همبستگی لازم
• محاسبه آمار تجمیعی با متغیرهای طبقه بندی
• ترسیم مدل های رگرسیون خطی برای ایجاد متغیرهای وابسته و روابط بین آنها
ماهیت منبع باز بودن و بسته محور بودن پایتون به متخصصان داده کمک می کند تا کارهای مختلفی با داده ها انجام دهند، از ورود و تحلیل داده گرفته تا مصورسازی و یادگیری ماشین. به هر حال برای همه این موارد برنامهنویس کار کمی برای انجام دادن نیاز دارد.

دیدگاه کاربران
0 دیدگاهشما هم دیدگاه خود را ارسال کنید